
Warum scheitern so viele KI-Projekte, noch bevor sie richtig starten?
- Schlecht organisierte Daten untergraben jedes Modell.
- KI kann nur aus den Daten lernen, die ihr zur Verfügung stehen.
- Unvollständige, inkonsistente oder verzerrte Daten = unzuverlässige Ergebnisse.
- Saubere, gut strukturierte Datenpipelines sind die Grundlage für skalierbare und vertrauenswürdige KI.
„Garbage in, garbage out" (GIGO) ist ein Begriff, den die meisten Datenfachleute gut kennen, und er trifft besonders in der Welt der KI zu. Ein Modell ist nur so gut wie die Daten, von denen es lernt. Hochwertige Daten können zu präzisen, vertrauenswürdigen Vorhersagen führen, während schlechte Daten nahezu garantiert fehlerhafte Ergebnisse liefern.
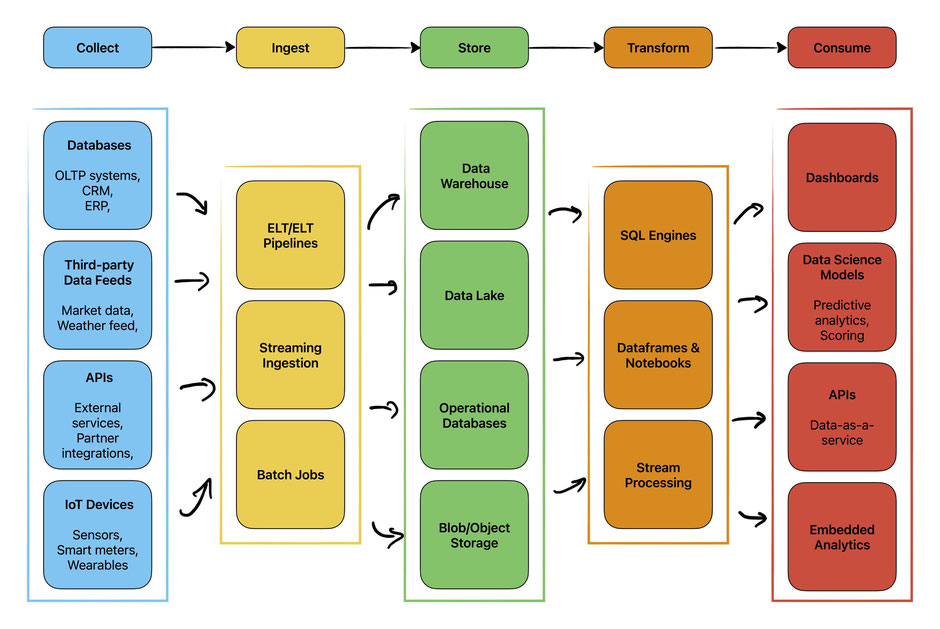
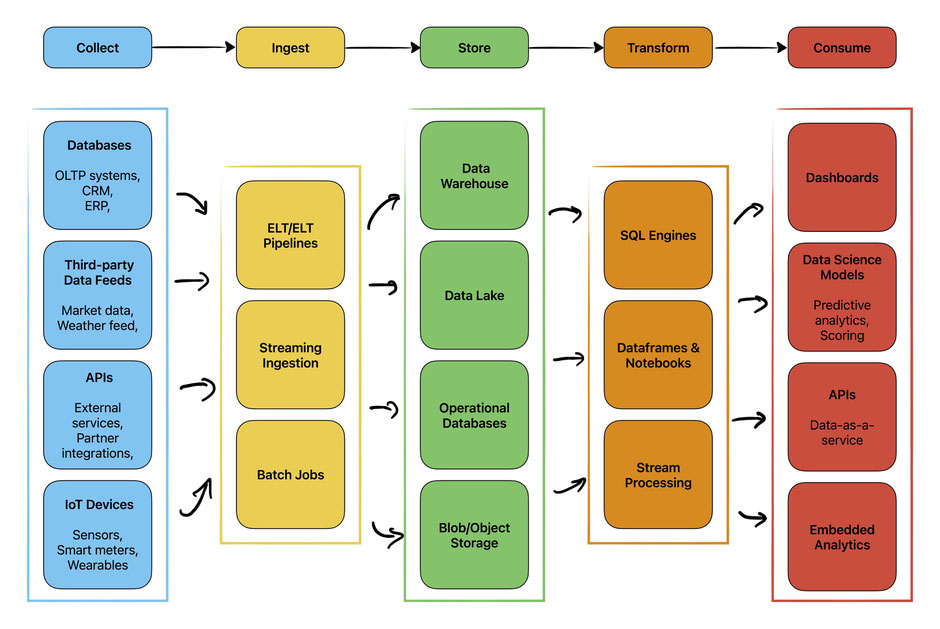
Deshalb ist das Verständnis für die Aufbereitung und Optimierung der eigenen Daten genauso wichtig wie die Modellierung selbst. Während moderne Plattformen wie Microsoft Fabric dabei helfen können, Teile des Prozesses zu automatisieren, ist es entscheidend, die fundamentalen Schritte hinter den Kulissen zu verstehen.
In dieser zweiteiligen Blog-Serie werden wir beide Seiten des Prozesses erkunden:
- Teil 1: Warum die Organisation von Daten wichtig ist und wie unsaubere Daten zu erheblichen Problemen führen.
- Teil 2: Eine praktische Anleitung zum Prototyping und Training eines XGBoost-Klassifikationsmodells für Kreditbewertungen in Python.
Dieser Ansatz spiegelt auch die reale Praxis wider: Erst die Daten richtig hinbekommen, dann den Fokus auf den Aufbau eines zuverlässigen, skalierbaren Modells legen.
Warum Datenorganisation für KI wichtig ist
Stellen Sie sich vor, Sie haben die Aufgabe, zu klassifizieren, ob Kunden eine gute oder schlechte Kreditwürdigkeit haben, basierend auf Merkmalen wie ihren früheren Krediten, der Rückzahlungshistorie, dem Nettoeinkommen oder den Ausgaben. Stellen Sie sich nun vor, dass bei einem Viertel der Kunden die Einkommenswerte fehlen, bei einem weiteren Viertel eine negative Zahl als Alter angegeben ist und mehrere Kunden doppelte IDs haben. Plötzlich wird es nahezu unmöglich, zuverlässige Entscheidungen zu treffen. Das verdeutlicht, warum organisierte, gut aufbereitete Daten so wichtig sind.
Trotz des Hypes um generative KI ist KI im Kern immer noch nur Algorithmen, die von Daten lernen. Viele der Fortschritte der letzten Jahre beruhen weniger auf völlig neuen Algorithmen als vielmehr auf dem gestiegenen Volumen und der Vielfalt der verfügbaren Trainingsdaten. Gut strukturierte und repräsentative Daten führen direkt zu präziseren und zuverlässigeren Modellen.
In sensiblen Anwendungsfällen wie der Kreditbewertung sind organisierte Daten auch unerlässlich, um Voreingenommenheit zu vermeiden. Wenn Trainingsdaten versteckte sozioökonomische Ungleichheiten widerspiegeln, kann das Modell unbeabsichtigt bestimmte Gruppen diskriminieren. Datenschutz ist ein weiteres Anliegen: Sensible Informationen müssen anonymisiert oder anderweitig geschützt werden, um Gesetzen und Vorschriften zu entsprechen. Ohne sorgfältige Organisation riskieren Sie, Modelle zu entwickeln, die unfair, nicht regelkonform oder unbrauchbar sind. Unter der EU-KI-Verordnung und den „Recht auf Erklärung"-Bestimmungen der DSGVO müssen KI-Systeme im Finanzwesen klare, interpretierbare Entscheidungen für Verbraucher liefern – Anforderungen, die mit unorganisierten zugrunde liegenden Daten unmöglich zu erfüllen sind.
Organisierte Daten sind auch die Grundlage für sinnvolles Feature Engineering, das oft mehr Einfluss auf die Leistung hat als die Wahl des Algorithmus selbst. Bei der Kreditbewertung können Sie beispielsweise nur Merkmale wie „durchschnittliche monatliche Ausgaben" oder „Anzahl der versäumten Zahlungen" ableiten, wenn die Rohtransaktionsdaten bereits konsistent und gut strukturiert sind. Schließlich können Automatisierungstools erst dann zuverlässig angewendet werden, wenn Datenpipelines standardisiert und organisiert sind. Ohne diese Grundlage skaliert Automatisierung lediglich das Chaos.
Modellauswahl: Datenqualität steht immer noch an erster Stelle
Sobald Ihre Daten organisiert sind, wird die Modellauswahl unkomplizierter. Bei der Kreditbewertung geht es oft darum, Genauigkeit, Erklärbarkeit und regulatorische Anforderungen auszubalancieren:
Die logistische Regression bleibt der Goldstandard in der regulierten Finanzbranche. Sie ist einfach, transparent und leicht prüfbar. Sie funktioniert gut mit sauberen, gut entwickelten Merkmalen, hat aber Schwierigkeiten mit komplexen nichtlinearen Mustern.
Gradient-Boosted Trees (XGBoost, LightGBM) sind zum Arbeitstier von ML-Produktionssystemen geworden, weil sie gemischte Datentypen gut handhaben und oft 5-15% bessere Leistung als lineare Modelle liefern. Sie erfordern jedoch eine sorgfältigere Überwachung von Voreingenommenheit und Modelldrift.
Neuronale Netzwerke können subtile Muster in großen, komplexen Datensätzen erfassen, sind aber datenhungrig und schwer zu erklären, was in regulierten Umgebungen oft ein Ausschlusskriterium ist.
Die wichtigste Erkenntnis: Ob Sie sich für die einfachste logistische Regression oder das ausgefeilteste Deep-Learning-Modell entscheiden, Ihr Erfolg wird immer noch durch die Datenqualität begrenzt. Der fortschrittlichste Algorithmus, der auf inkonsistenten, voreingenommenen oder unvollständigen Daten trainiert wurde, wird unzuverlässige Ergebnisse produzieren. Saubere Pipelines kommen zuerst; erst dann spielt die Modellwahl eine Rolle.
Fazit
Die Lehre ist einfach: Daten zuerst, Modell danach. Bringen Sie Ihre Pipelines in Ordnung, und jeder Modellierungsschritt wird einfacher und zuverlässiger. In Teil 2 werden wir dies mit einem XGBoost-Prototyp für Kreditbewertungen in die Praxis umsetzen.
Why Poor Data Organization Kills AI Projects Before They Start.
Why do so many AI projects fail before they even begin?
- Poorly organized data undermines every model.
- AI can only learn from the data it's given.
- Inconsistent, incomplete, or biased data = unreliable outcomes.
- Clean, well-structured pipelines are the foundation of scalable, trustworthy AI.
"Garbage in, garbage out" (GIGO) is a phrase most data professionals know well, and it is especially true in the world of AI. A model is only as good as the data it learns from. High-quality data can drive accurate, trustworthy predictions, while poor data almost guarantees flawed results.
That is why understanding how to prepare and optimize your own data is just as important as the modeling itself. While modern platforms like Microsoft Fabric can help automate parts of the process, it is critical to grasp the fundamental steps behind the scenes.
In this two-part blog series, we will explore both sides of the process:
- Part 1: Why organizing data matters, and how unclean data can cause major issues.
- Part 2: A hands-on walk-through of prototyping and training an XGBoost classification model for credit rating in Python.
This approach also mirrors real-world practice: first, get the data right, then focus on building a reliable, scalable model.
Why Organizing Data Matters for AI
Imagine you’re tasked with classifying whether customers have a good or bad credit rating based on features such as their previous loans, repayment history, net income, or expenses. Now imagine that a quarter of the customers have missing income values, another quarter have a negative number listed as their age, and several customers share duplicate IDs. Suddenly, it becomes nearly impossible to make reliable decisions. This gets to the heart of why organized, well-prepared data matters so much.
Despite the hype around generative AI, AI at its core is still just algorithms learning from data. Many of the advancements in recent years are less about brand-new algorithms and more about the increased volume and diversity of data available to train them. Well-structured and representative data directly translates into more accurate and reliable models.
In sensitive use cases like credit rating, organized data is also essential for avoiding bias. If training data reflects hidden socioeconomic disparities, the model may inadvertently discriminate against certain groups. Data privacy is another concern: sensitive information must be anonymized or otherwise safeguarded to comply with laws and regulations. Without careful organization, you risk building models that are unfair, non-compliant, or unusable. Under the EU's AI Act and GDPR's "right to explanation" provisions, financial AI systems must provide clear, interpretable decisions to consumers—requirements that become impossible to meet with disorganized underlying data.
Organized data is also the foundation for meaningful feature engineering, which often has more impact on performance than the choice of algorithm itself. In credit rating, for example, you can only derive features such as “average monthly spend” or “number of missed payments” if the raw transaction data is already consistent and well-structured. Finally, once data pipelines are standardized and organized, automation tools can be applied reliably. Without that foundation, automation simply scales the mess.
Choosing Models: Data Quality Still Comes First
Once your data is organized, model selection becomes more straightforward. In credit scoring, the choice often comes down to balancing accuracy, explainability, and regulatory requirements: Logistic regression remains the gold standard in regulated finance. Simple, transparent, and easily auditable. It works well with clean, well-engineered features but struggles with complex non-linear patterns.
Gradient-boosted trees (XGBoost, LightGBM) have become the workhorse of production ML systems because they handle mixed data types well and often deliver 5-15% better performance than linear models. However, they require more careful monitoring for bias and model drift.
Neural networks can capture subtle patterns in large, complex datasets but are data-hungry and difficult to explain, which is often a non-starter in regulated environments.
The key insight: whether you choose the simplest logistic regression or the most sophisticated deep learning model, your success is still constrained by data quality. The most advanced algorithm trained on inconsistent, biased, or incomplete data will produce unreliable results. Clean pipelines come first; only then does model choice matter.
Conclusion
The lesson is simple: data first, model second. Get your pipelines right, and every modeling step becomes easier and more reliable. In Part 2, we will put this into action with an XGBoost prototype for credit ratings.
Kommentar schreiben