
20. März 2026
In diesem Beitrag zeige ich, worin sich beide Datentypen unterscheiden, warum das für Analytics und KI entscheidend ist – und wie Unternehmen damit strategisch umgehen sollten.

10. Dezember 2025
Datenqualität (DQ) ist entscheidend für den Erfolg von Analytics Engineering und KI-Anwendungen. Trotz hoher Investitionen in Datenmodernisierung bleiben Datenqualitätsprobleme bestehen, was die Effektivität von Datenteams beeinträchtigt. Um DQ zu verbessern, sind verteilte Verantwortung, systematische Tool-Nutzung und proaktive Datenstrategien notwendig.

28. November 2025
Trotz Investitionen in Datenmodernisierung bestehen Datensilos und Qualitätsprobleme in Finanzinstituten. Ursachen sind regulatorischer Druck, M&A-Aktivitäten und Autonomie der Geschäftsbereiche. Erfolgreiche Lösungen beginnen mit regulatorischen Anwendungsfällen, setzen auf föderierte Verantwortlichkeit und verfolgen einen inkrementellen Integrationsansatz.
Photo by Eren Li: https://www.pexels.com/photo/photo-of-magnifying-glass-on-top-of-braille-7188802/

14. November 2025
In diesem Blog beschreiben wir die Rolle in einem typischen modernen Datenteam und wie diese miteinander arbeiten. Außerdem sprechen wir darüber, wie Sie herausfinden können, welchen Rollen am besten zu den aktuellen Datenanforderungen Ihres Unternehmens passen.
Foto von Annie Spratt auf Unsplash

06. November 2025
In diesem Blog erklären wir, was Data Warehouse as a Service (DWaaS) ist und wie es funktioniert. Wir behandeln die wichtigsten Vorteile, darunter Kosteneffizienz, Skalierbarkeit und reduzierter Verwaltungsaufwand, und diskutieren, wer die Einführung in Betracht ziehen sollte. Außerdem untersuchen wir, wie Multicloud- und Hybrid-Architekturen die Zuverlässigkeit und Ausfallsicherheit Ihrer Dateninfrastruktur verbessern können.

29. Oktober 2025
Erfahren Sie, wie Data Fabric und Data Mesh zusammenwirken, um getrennte Datensysteme zu vereinheitlichen und technologische Infrastruktur mit organisatorischer Klarheit zu verbinden.

23. Oktober 2025
Der AWS-Ausfall vom 20. Oktober betraf weltweit Millionen Nutzer über 15 Stunden. Ein guter Anlass, über Cloud-Konzentration und Resilienz-Strategien nachzudenken.
In unserem Blogbeitrag: Multi-Cloud-Architekturen, Hybrid-Ansätze und Compliance-Überlegungen für kritische Infrastrukturen.
Besonders relevant für Finanzwesen, Gesundheitswesen und öffentliche Dienste.

16. Oktober 2025
Überblick über die Data-Mesh-Architektur / Overview of the Data Mesh Architecture
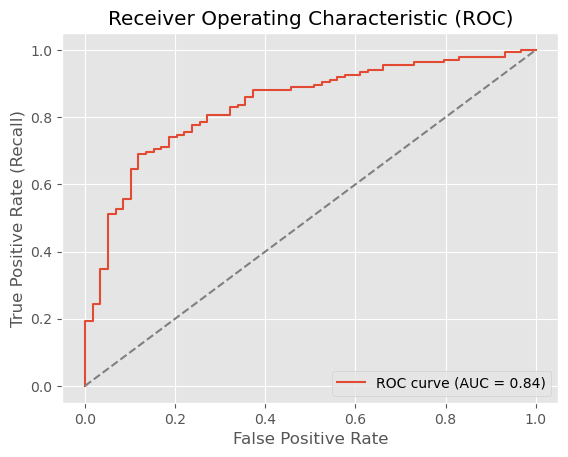
06. Oktober 2025
So trainieren Sie einen XGBoost-Kreditklassifikator in Python – von der Datenbereinigung bis zur Modellbewertung mit praxisnahen Beispielen.
Learn how to train an XGBoost credit classifier in Python – from data cleaning to model evaluation with hands-on code examples.

30. September 2025
**Warum schitern so viele KI-Projekte, noch bevor sie richtig starten?**
- Schlecht organisierte Daten untergraben jedes Modell.
- KI kann nur aus den Daten lernen, die ihr zu Verfügung stehen.
- Unvollständige, inkonsistente oder verzerrte Daten = unzuverlässige Ergebnisse.
- Saubere, gut strukturierte Datenpipelines sind die Grundlage für skalierbare und vertrauenswürdige KI.