
In diesem Blog beschreiben wir die Rolle in einem typischen modernen Datenteam und wie diese miteinander arbeiten. Außerdem sprechen wir darüber, wie Sie herausfinden können, welchen Rollen am besten zu den aktuellen Datenanforderungen Ihres Unternehmens passen.
- Datenteams sind aufgrund des zunehmenden Umfangs und der Komplexität von Daten größer und spezialisierter geworden.
- Die Struktur von Datenteams variiert je nach Unternehmen und hängt von Faktoren wie Datenvolumen, Quellkomplexität und Anforderungen der nachgelagerten Prozesse ab.
- Beschreibung der Hauptverantwortlichkeiten jeder Rolle und ihrer Einbindung ins Team, mit einem Beispiel dafür, wie das Datenteam gemeinsam arbeiten würde.
- In kleineren Teams überschneiden sich Rollen häufig, wobei Einzelpersonen mehrere Verantwortlichkeiten übernehmen. Die Zusammensetzung eines Datenteams sollte sich mit der Reife des Unternehmens und seinen Datenanforderungen weiterentwickeln – beginnend mit Generalisten und bei Bedarf ergänzt durch Spezialisten.
- Datenrollen entwickeln sich kontinuierlich weiter durch die Einführung neuer Technologien wie KI und dbt, was zu einer stärkeren Bedeutung von Analytics Engineering und KI-Engineering führt.
Heutige Datenteams sehen deutlich anders aus als noch vor einiger Zeit. Da Menge und Komplexität von Daten und Datenquellen rasant zunehmen, sind auch die Datenteams komplexer geworden, oft größer und mit stärker spezialisierten Rollen. Gleichzeitig haben sich einige Rollen – wie etwa die des Data Engineers – eher verbreitert als verengt und umfassen inzwischen Aufgaben wie Python-Entwicklung, Cloud-Konfiguration oder CI/CD. Wie genau ein Datenteam aufgebaut ist, unterscheidet sich jedoch von Unternehmen zu Unternehmen und hängt von verschiedenen Faktoren ab, etwa davon, wie viele Daten wie schnell verarbeitet werden müssen, wie komplex die Datenquellen sind und welche Anforderungen nachgelagerte Stakeholder an das Team stellen. Wichtig ist dabei, dass es in den meisten Unternehmen Überschneidungen in den Zuständigkeiten der Teammitglieder gibt und nicht alle Rollen, die wir in diesem Blog beschreiben, immer strikt getrennt sind.
In diesem Blog werfen wir einen Blick auf die gesamte „Daten-Wertschöpfungskette" und betrachten dann die häufigsten Rollen in modernen Datenteams und schauen uns an, wie jede Rolle hineinpasst und wofür sie verantwortlich ist.
Was macht ein ... ?
Wir beginnen damit, die typischen Verantwortlichkeiten für jede Rolle zu beschreiben und wie sie innerhalb des Datenteams eingebunden ist.
Data Architect
Data Architects sind die strategischen Planer und Designer der Dateninfrastruktur einer Organisation. Sie sind dafür verantwortlich, den Blueprint zu erstellen, der bestimmt, wie Daten durch die Organisation fließen, wie sie gespeichert werden und wie verschiedene Systeme miteinander verbunden sind und kommunizieren. Im täglichen Geschäft bewerten sie Technologieentscheidungen, entwerfen Datenmodelle und Schemas, etablieren Data-Governance-Frameworks und stellen sicher, dass die gesamte Datenarchitektur skalierbar und sicher ist. Sie arbeiten eng mit Stakeholdern in der gesamten Organisation zusammen, um Anforderungen zu verstehen und diese in technische Spezifikationen zu übersetzen, die leiten, wie sich die Dateninfrastruktur im Laufe der Zeit entwickelt.
Data Engineer / Analytics Engineer
Data Engineers sind die Erbauer und Betreuer der Dateninfrastruktur, auf die sich der Rest des Teams verlässt. Sie entwickeln und pflegen die Pipelines, die Daten aus verschiedenen Quellen extrahieren, sie in nutzbare Formate transformieren und in Data Warehouses oder Data Lakes laden, wo sie von Analysten und Data Scientists abgerufen werden können. Im täglichen Geschäft schreiben sie Code zur Automatisierung von Daten-Workflows, überwachen die Pipeline-Performance, beheben Datenqualitätsprobleme und optimieren die Datenverarbeitung hinsichtlich Geschwindigkeit und Zuverlässigkeit. Analytics Engineers befinden sich an der Schnittstelle zwischen Data Engineering und Analytics und konzentrieren sich speziell darauf, Rohdaten in saubere und gut modellierte Datensätze zu transformieren, die für Geschäftsanalysen bereit sind. Sie arbeiten oft auch mit Tools wie dbt, um Transformationslogik zu erstellen und sicherzustellen, dass Datendefinitionen in der gesamten Organisation konsistent sind.
Data Analyst / BI Analyst
Data Analysts sind die Übersetzer zwischen Daten und Geschäftsentscheidungen. Sie analysieren Daten, um Erkenntnisse aufzudecken, Geschäftsfragen zu beantworten und Stakeholdern zu helfen, fundierte Entscheidungen zu treffen. Ihre tägliche Arbeit umfasst das Schreiben von SQL-Abfragen zur Datenextraktion, das Erstellen von Visualisierungen und Dashboards in BI-Tools wie Tableau oder PowerBI, das Durchführen explorativer Analysen zur Identifizierung von Trends und Mustern sowie das Präsentieren von Ergebnissen für nicht-technische Stakeholder. Sie arbeiten eng mit Geschäftsteams zusammen, um deren Bedürfnisse zu verstehen und Rohdaten in umsetzbare Empfehlungen zu verwandeln. BI Analysts konzentrieren sich speziell auf den Aufbau und die Pflege der Reporting-Infrastruktur, die Self-Service-Analytics in der gesamten Organisation ermöglicht.
Data Scientist / Machine Learning Engineer
Data Scientists nutzen statistische Methoden und maschinelles Lernen, um tiefere Erkenntnisse zu gewinnen und prädiktive Modelle zu erstellen. Sie gehen über deskriptive Analysen hinaus, um Fragen wie „Was wird passieren?" und „Warum ist das passiert?" zu beantworten. Im täglichen Geschäft entwickeln sie Hypothesen, entwerfen Experimente, bauen und trainieren Machine-Learning-Modelle und kommunizieren komplexe Erkenntnisse an Stakeholder. Machine Learning Engineers nehmen die Modelle, die Data Scientists entwickeln, und bringen sie in die Produktion. Sie verwandeln experimentellen Code in zuverlässige, skalierbare Systeme, die Vorhersagen in Echtzeit oder durch Batch-Prozesse treffen können.
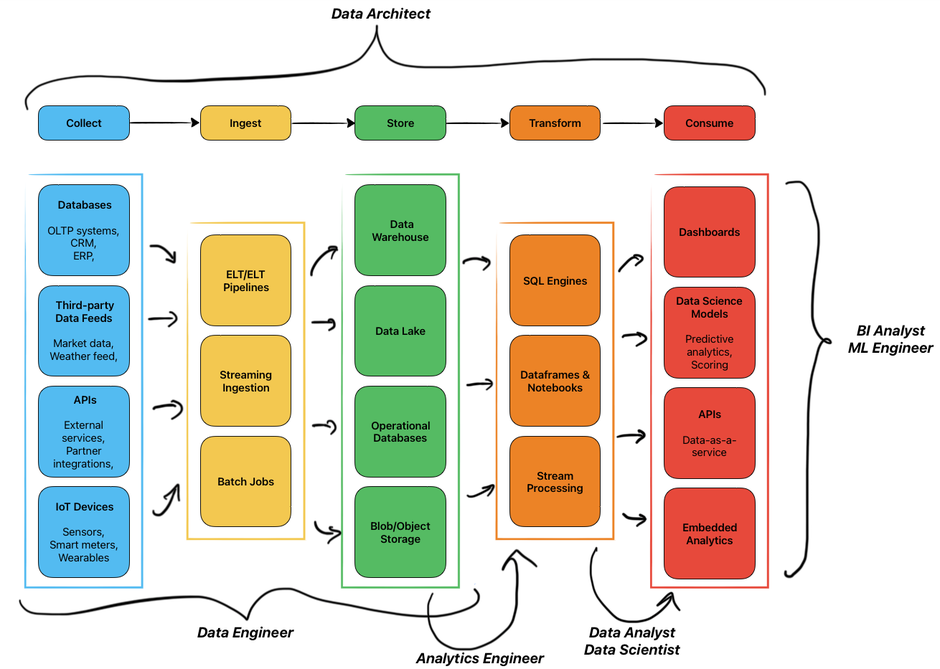
Wie diese Rollen zusammenarbeiten
Nachdem wir nun eine Vorstellung davon haben, wofür jede Rolle verantwortlich ist, schauen wir uns an, wie ein Datenteam in einem Beispielszenario zusammenarbeitet. Stellen wir uns vor, Ihr Unternehmen möchte vorhersagen, welche Kunden wahrscheinlich ihre Abonnements kündigen werden. So arbeiten verschiedene Rollen zusammen:
Der Data Architect bewertet zunächst, ob die aktuelle Infrastruktur diese Initiative unterstützen kann. Er bestimmt, wo Kundeninteraktionsdaten gespeichert werden sollen, wie lange sie aufbewahrt werden sollen, und stellt sicher, dass die Architektur sowohl Echtzeit- als auch historische Analysen unterstützt.
Data Engineers bauen dann die Pipelines, um Daten aus verschiedenen Quellen zu sammeln. Sie stellen sicher, dass diese Daten zuverlässig in Ihr Data Warehouse fließen. Analytics Engineers greifen ein, um diese Rohdaten in saubere, gut strukturierte Tabellen zu transformieren, die alle relevanten Kundeninformationen in einer einheitlichen Ansicht kombinieren.
Data Analysts erkunden diese Daten, um Muster zu identifizieren. Zum Beispiel entdecken sie möglicherweise, dass Kunden, die sich 14 Tage lang nicht angemeldet haben oder mehrmals den Support kontaktiert haben, eher zur Abwanderung neigen. Sie erstellen Dashboards, die es dem Unternehmen ermöglichen, diese Frühwarnsignale zu überwachen.
Data Scientists führen diese Erkenntnisse weiter, indem sie ein prädiktives Modell erstellen, das für jeden Kunden eine Abwanderungswahrscheinlichkeit berechnet. Schließlich setzen Machine Learning Engineers dieses Modell in Produktion ein, stellen sicher, dass es jede Nacht automatisch läuft und mit Ihrem Marketing-Automatisierungssystem integriert ist, um Kundenbindungskampagnen auszulösen.
Allerdings benötigt nicht jede Organisation all diese Rollen als separate Positionen. In kleineren Teams überschneiden sich diese Verantwortlichkeiten oft erheblich. Ein Data Engineer könnte auch Analytics-Engineering-Aufgaben übernehmen. Ein Data Analyst könnte einfache Machine-Learning-Modelle erstellen. Ein Data Scientist könnte seine eigenen Modelle deployen. Die Entscheidung zur Spezialisierung hängt vom Umfang, der Komplexität und dem Arbeitsvolumen in jedem Bereich ab. Ein Startup mit drei Datenteammitgliedern wird natürlich mehr Rollenüberschneidungen haben als ein Unternehmen mit einer 50-köpfigen Datenorganisation.
Welche Rolle ist die richtige für Ihre Organisation
Die Zusammensetzung Ihres Datenteams sollte sich mit der Reife und den Datenanforderungen Ihres Unternehmens entwickeln. Was meinen wir damit genau? Lassen Sie uns das mit einigen Beispielen verdeutlichen.
Wenn Ihre Organisation klein ist, sollten Sie mit Generalisten beginnen, die mehrere Hüte tragen können. Ihre erste Einstellung sollte typischerweise ein Data Analyst oder Analytics Engineer sein, der grundlegendes Reporting einrichten, Geschäftsfragen beantworten und einfache Datenpipelines aufbauen kann. Während Sie wachsen, fügen Sie einen Data Engineer hinzu, um robustere Pipelines zu bauen, wenn sich Ihre Datenquellen vermehren.
Wenn die Organisation noch weiter wächst, möchten Sie vielleicht in Betracht ziehen, dass sich Data Engineers ausschließlich auf die Infrastruktur konzentrieren, Data Analysts auf Geschäftseinblicke und Analytics Engineers die Lücke schließen, indem sie sicherstellen, dass Daten konsistent modelliert werden. Wenn Ihr Geschäft von Vorhersagen oder Empfehlungen abhängt, ist dies der Punkt, an dem Sie wahrscheinlich einen Data Scientist oder einen Machine Learning Engineer einbringen sollten. Die meisten Senior Engineers können architektonische Entscheidungen gemeinsam treffen, und daher gibt es normalerweise noch keinen Bedarf für einen dedizierten Data Architect.
Erst wenn Ihre Organisation auf über hundert Mitarbeiter anwächst (offensichtlich wird diese Zahl nur als grobes Beispiel verwendet), wird Spezialisierung notwendig. Sie sollten idealerweise separate Teams für Engineering, Analytics und Data Science haben. Ein Data Architect sorgt für Kohärenz in Ihrem komplexen Ökosystem. Machine Learning Engineers bilden ihr eigenes Team, das sich auf ML-Infrastruktur konzentriert, getrennt von Data Scientists, die sich auf Forschung und Modellentwicklung konzentrieren.
Fazit
Mit dieser Beschreibung der einzelnen Rollen möchten wir Ihnen einen besseren Überblick darüber verschaffen, was jede dieser Rollen beinhaltet und wie sie sich in ein modernes Datenteam einfügen. Es gibt gute Gründe zu erwarten, dass sich diese Rollen mit der Einführung von KI-Tools weiterentwickeln werden. Mit dem Aufkommen von dbt beispielsweise ist der Begriff „Analytics Engineering” viel geläufiger geworden. Ebenso sind KI-Ingenieure heute viel häufiger anzutreffen, da generative KI immer weiter verbreitet ist.
Wir stellen Ihnen ein kostenloses Entscheidungsframework zur Verfügung, das Ihnen dabei hilft, den individuellen Datenbedarf Ihrer Organisation zu bestimmen – denn eine pauschale Lösung gibt es nicht. Die optimale Struktur richtet sich immer nach Ihrem Reifegrad, Ihren Anforderungen und Ihren strategischen Prioritäten.
Wir hoffen, dass Ihnen dieser Blogbeitrag gefallen hat. Wenn Sie Unterstützung dabei wünschen, Ihren aktuellen Stand auf Ihrer Data Journey einzuschätzen oder Ihren bestehenden Stack auszubauen bzw. zu optimieren, helfen wir Ihnen jederzeit gern weiter.
How does a modern data team look like?
In this blog, we describe the roles in a typical modern data team and how they work together. We also discuss how you can determine which roles best fit your organization's current data requirements.
- Data teams have become larger and more specialized due to the increasing volume and complexity of data.
- Data team structure varies by company based on factors like data volume, source complexity, and downstream needs.
- Description of each role's main responsibilities and how they fit in the team with an example of how the data team would work collaboratively
- In smaller teams, roles often overlap, with individuals handling multiple responsibilities. The composition of a data team should evolve with the company’s maturity and data needs, starting with generalists and adding specialists as needed.
- Data roles are constantly evolving with the adoption of new technologies like AI and dbt, leading to increased prominence of analytics engineering and AI engineering.
Data teams today look distinctly different from what they looked like not too long ago. With the amount and complexity of data and data sources increasing rapidly, data teams have also become more complex to adapt, usually increasing in size and with roles getting more specialized. At the same time, some roles, such as data engineering, have broadened rather than narrowed, now encompassing tasks like Python development, cloud configuration, and CI/CD. How exactly a data team is structured is different from company to company, based on a number of factors, such as how much and how quickly data needs to be handled, the complexity of data sources, and the needs from the data team downstream, just to name a few. The important point is that each company usually has overlapping roles for its data team members and not all of the roles that we describe in this blog are necessarily separate all the time.
In this blog, we will take a look at the 'data value chain' as a whole and then have a look at the most common roles found in modern data teams and look at how each role fits in and what they are responsible for.
What does a ... do?
We begin by describing what the typical responsibilities for each role are and how they fit within the data team.
Data Architect
Data Architects are the strategic planners and designers of an organization's data infrastructure. They're responsible for creating the blueprint that determines how data flows through the organization, how it's stored, and how different systems connect and communicate with each other. On a daily basis, they evaluate technology choices, design data models and schemas, establish data governance frameworks, and ensure that the overall data architecture is scalable and secure. They work closely with stakeholders across the organization to understand requirements and translate them into technical specifications that guide how the data infrastructure evolves over time.
Data Engineer / Analytics Engineer
Data Engineers are the builders and maintainers of the data infrastructure that the rest of the team relies on. They develop and maintain the pipelines that extract data from various sources, transform it into usable formats, and load it into data warehouses or lakes where it can be accessed by analysts and data scientists. Day-to-day, they write code to automate data workflows, monitor pipeline performance, troubleshoot data quality issues, and optimize data processing for speed and reliability. Analytics Engineers sit at the intersection of data engineering and analytics, focusing specifically on transforming raw data into clean and well-modeled datasets that are ready for business analysis. They also often work in tools like dbt to create transformation logic and ensure data definitions are consistent across the organization.
Data Analyst / BI Analyst
Data Analysts are the translators between data and business decisions. They analyze data to uncover insights, answer business questions, and help stakeholders make informed decisions. Their daily work involves writing SQL queries to extract data, creating visualizations and dashboards in BI tools like Tableau or PowerBI, conducting exploratory analysis to identify trends and patterns, and presenting findings to non-technical stakeholders. They work closely with business teams to understand their needs and turn raw data into actionable recommendations. BI Analysts specifically focus on building and maintaining the reporting infrastructure that enables self-service analytics across the organization.
Data Scientist / Machine Learning Engineer
Data Scientists use statistical methods and machine learning to extract deeper insights and build predictive models. They go beyond descriptive analytics to answer questions like 'what will happen?' and 'why did this happen?'. On a daily basis, they develop hypotheses, design experiments, build and train machine learning models, and communicate complex findings to stakeholders. Machine Learning Engineers take the models that data scientists develop and productionize them. They turn experimental code into reliable, scalable systems that can make predictions in real-time or through batch processes.
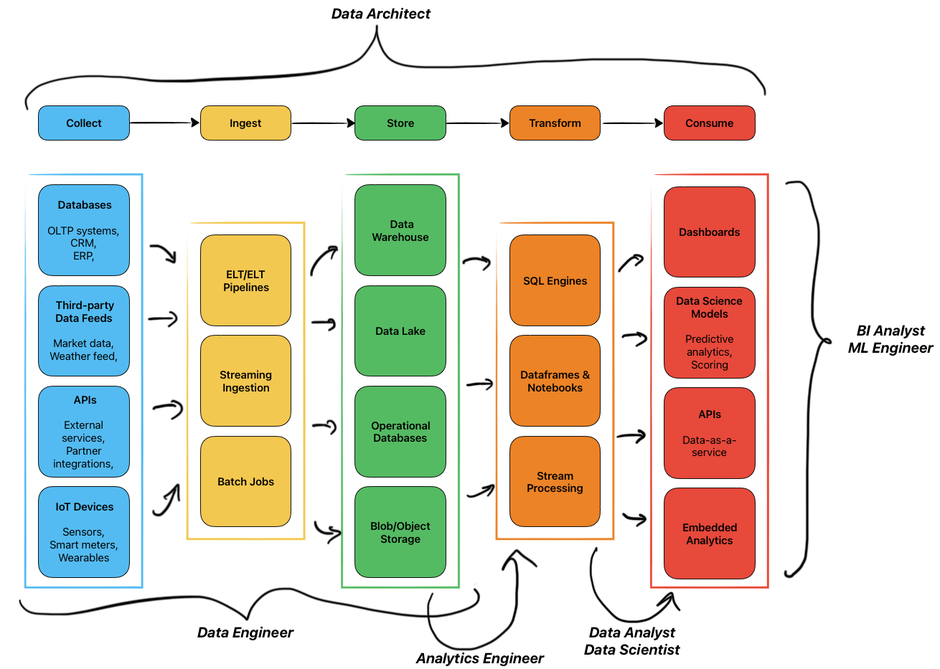
How These Roles Work Together
Now that we have an idea about what each role is responsible for, let's look at how a data team works together in an example scenario. Let's imagine your company wants to predict which customers are likely to cancel their subscriptions. Here's how different roles collaborate:
The data architect first assesses whether the current infrastructure can support this initiative. They determine where customer interaction data should be stored, how long to retain it, and ensure the architecture supports both real-time and historical analysis.
Data engineers then build the pipelines to collect data from various sources. They ensure this data flows reliably into your data warehouse. Analytics engineers step in to transform this raw data into clean, well-structure tables that combine all relevant customer information into a unified view.
Data analysts explore this data to identify patterns. For example, perhaps they discover that customers who haven't logged in for 14 days or contacted support multiple times are more likely to churn. They create dashboards that let the business monitor these early warning signs.
Data scientists take these insights further by building a predictive model that calculates a churn probability score for each customer. Finally, machine learning engineers deploy this model into production, ensuring it runs automatically each night and integrates with your marketing automation system to trigger retention campaigns.
However, not every organization needs all these roles as separate positions. In smaller teams, these responsibilities often overlap significantly. A data engineer might also handle analytics engineering tasks. A data analyst might build simple machine learning models. A data scientist might deploy their own models. The decision to specialize depends on the scale, complexity, and the volume of work in each area. A startup with three data team members will naturally have more role overlap than an enterprise with a 50-person data organization.
Which Role is Right for Your Organization
The composition of your data team should evolve with your company's maturity and data needs. What do we mean by this exactly? Let's clarify with some examples.
When your organization is small, you want to start with generalists who can wear multiple hats. Your first hire should typically be a data analyst or analytics engineer who can set up basic reporting, answer business questions, and build simple data pipelines. As you grow, add a data engineer to build more robust pipelines as your data sources multiply.
As the organization grows even more, you might want to consider having data engineers focus exclusively on infrastructure, data analysts on business insights, and analytics engineers to bridge the gap by ensuring data is modeled consistently. If your business depends on predictions or recommendations, this is the point you should probably bring in a data scientist or a machine learning engineer. Most senior engineers can handle architectural decisions collaboratively and as such there is usually no need for a dedicated data architect yet.
It is only when your organization grows to over a hundred employees (obviously this number is used just as a rough example) that specialization becomes necessary. You should ideally have separate teams for engineering, analytics, and data science. A data architect maintains coherence across your complex ecosystem. Machine learning engineers form their own team focused on ML infrastructure, separate from data scientists who focus on research and model development.
Conclusion
By outlining these roles, we wanted to give you a better idea of what each of these them do and how they all fit in a modern data team. There are good reasons to expect these roles to keep evolving with the adoption of AI tools. For example, with the advent of dbt, the usage of analytics engineering as a term has become a lot more common. Similarly, AI engineers are a lot more common now given how widespread generative AI is becoming.
We offer a complimentary decision framework to help you identify your organization unique data needs, because there is no one-size-fits-all solution. The right setup depends on your stage of maturity, your requirements, and your strategic priorities.
We hope you enjoyed this blog post. If you'd like support in understanding where you are on your data journey or in expanding or optimizing your current stack, we're always happy to help.
Kommentar schreiben