
Wie baut man einen XGBoost-Kreditklassifikator in Python?
- Datenqualität ist entscheidend für präzise Kreditmodelle.
- Schritt-für-Schritt von Rohdaten über Bereinigung bis zum Training.
- XGBoost liefert solide Ergebnisse (ROC AUC ≈ 0,84).
- Grundlage für skalierbare, automatisierbare Kreditbewertungssysteme.
In unserem letzten Beitrag haben wir die Bedeutung von Datenorganisation und -qualität diskutiert. Falls Sie ihn verpasst haben, hier die wichtigste Erkenntnis: Schlechte Datenorganisation ist einer der Hauptgründe, warum KI-Projekte scheitern, bevor sie überhaupt beginnen.
Unvollständige, inkonsistente oder verzerrte Daten führen zu unzuverlässigen Ergebnissen, egal wie fortschrittlich das Modell ist. In sensiblen Bereichen wie dem Kreditscoring sind saubere und gut strukturierte Daten entscheidend für Genauigkeit, Fairness und regulatorische Compliance. Automatisierung und Feature Engineering funktionieren nur, wenn sie auf einer soliden Datenbasis aufbauen.
Das Fazit? Sichern Sie zuerst die Datenqualität, dann wählen Sie das richtige Modell. Andersherum funktioniert es nicht.
In diesem Beitrag werden wir einen Credit-Scoring-Prototyp mit XGBoost implementieren. Sobald die Daten richtig vorbereitet sind, werden Sie sehen, wie unkompliziert das Modelltraining sein kann. Wir behandeln die relevanten Code-Abschnitte in diesem Blog, aber erkunden Sie gerne den vollständigen Quellcode auf GitHub für tiefergehende Implementierungsdetails.
Während Kreditscoring-Systeme in Deutschland interpretierbare Methoden wie logistische Regression erfordern, demonstriert dieser XGBoost-Prototyp Best Practices, die für jeden Data Scientist essenziell sind. In der Praxis entwickeln Teams routinemäßig zuerst Gradient-Boosting-Modelle, um einen Performance-Benchmark zu etablieren und die aussagekräftigsten Merkmale zu identifizieren, Erkenntnisse, die direkt in das Design einfacherer, konformer Modelle einfließen. Darüber hinaus lassen sich diese Techniken auf Kreditscoring in internationalen Märkten sowie auf internes Risiko-Modeling anwenden, wo regulatorische Anforderungen unterschiedlich ausfallen.
Datenaufbereitung
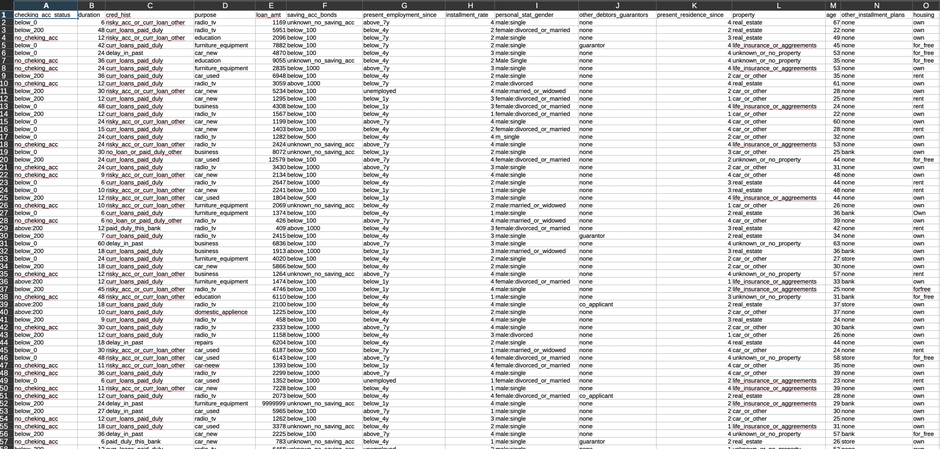
Wir verwenden einen Finanzdatensatz mit Kundendaten und verschiedenen Attributen, die zur Bestimmung von „guten" oder „schlechten" Bonitätsbewertungen verwendet werden. Der Datensatz enthält sowohl numerische Merkmale (Einkommen, Alter, Darlehensbetrag) als auch kategoriale Merkmale (Beschäftigungsstatus, Wohnform, Darlehenszweck).
Um reale Bedingungen zu simulieren, haben wir absichtlich häufige Datenqualitätsprobleme in den ursprünglichen Datensatz eingeführt: fehlende Werte, Duplikate, Ausreißer und inkonsistente Formatierung. Während die Originaldaten bereits bereinigt waren, ermöglichen uns diese künstlichen Unvollkommenheiten, die vollständige Datenbereinigungspipeline zu demonstrieren, die Sie in Produktionsumgebungen benötigen würden.
Wie erwartet gibt es ein erhebliches Klassenungleichgewicht, wobei die Mehrheit der Kunden als „gut" bewertet wird. Dies spiegelt die reale Kreditvergabe wider: Die meisten Menschen geraten nicht in Zahlungsverzug. Während dies eine ausgezeichnete Nachricht für Kreditgeber ist, stellt es eine erhebliche Herausforderung für Data Scientists dar. Klassenungleichgewicht erschwert es Klassifikationsmodellen, Muster in der Minderheitsklasse zu lernen, was oft zu Modellen führt, die einfach für jeden „gut" vorhersagen und dabei eine täuschend hohe Genauigkeit erzielen.
Der Datenbereinigungsprozess
Um diese Probleme anzugehen, führen wir eine umfassende Datenbereinigungspipeline (german_credit_cleanser.py) aus, die systematisch nach Folgendem sucht:
- Duplikate – die bestimmte Muster künstlich verstärken und das Modell verzerren können
- Fehlende Werte – die je nach fehlendem Anteil eine Imputation oder Entfernung erfordern
- Ungültige Werte – wie negative Altersangaben oder Darlehenssummen, die vernünftige Schwellenwerte überschreiten
- Ausreißer – Extremwerte, die eher Dateneingabefehler als legitime Randfälle darstellen können
- Datentypkonsistenz – Sicherstellung, dass numerische Felder numerisch sind und kategoriale Felder ordnungsgemäß kodiert sind
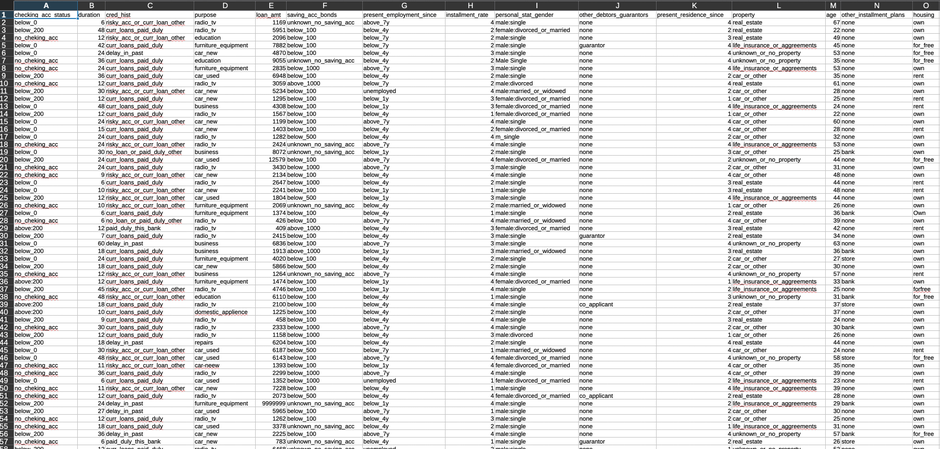
Nach Ausführung des Bereinigungsskripts erhalten wir einen verfeinerten Datensatz mit 968 Zeilen, der für das Modelltraining bereit ist. Obwohl wir einige Datensätze im Bereinigungsprozess verloren haben, sind die verbleibenden Daten zuverlässig und wir können ihnen vertrauen, um aussagekräftige Vorhersagen zu treffen.
Training Ihres modells mit XGBoost
Datenvorverarbeitungsschritte
Mit sauberen Daten können wir zum Modelltraining übergehen. Bevor wir das Modell anpassen, müssen wir die Daten im entsprechenden Format für XGBoost vorbereiten.
Zunächst kodieren wir die Zielvariable (gute/schlechte Bonitätsbewertung) als numerische Labels mit sklearn's LabelEncoder:
# Target encoding
y = df['target'].astype(str)
le = LabelEncoder()
y_enc = le.fit_transform(y)
X = df.drop(columns=['target'])
Als Nächstes führen wir eine stratifizierte Train-Test-Aufteilung (80/20) durch, um die gleiche Klassenverteilung in beiden Sets beizubehalten und Data Leakage zu verhindern:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
Für kategoriale Merkmale in unserem Datensatz konvertieren wir sie in pandas' category Datentyp, den XGBoost nativ verarbeiten kann, ohne One-Hot-Encoding zu benötigen:
categorical_columns = ['employment_status', 'housing', 'purpose']
for col in categorical_columns:
X_train[col] = X_train[col].astype('category')
X_test[col] = X_test[col].astype('category')
Schließlich berechnen wir den Skalierungsfaktor für das Klassenungleichgewicht, den XGBoost verwenden wird, um der Minderheitsklasse während des Trainings mehr Gewicht zu geben:
scale_pos_weight = (y_train == 0).sum() / (y_train == 1).sum()
Modelltraining
Wir instanziieren und trainieren den XGBoost-Klassifikator mit optimierten Hyperparametern:
model = XGBClassifier(
scale_pos_weight=scale_pos_weight,
max_depth=6,
learning_rate=0.1,
n_estimators=100,
enable_categorical=True,
random_state=42
)
model.fit(X_train, y_train)
Die wichtigsten Parameter sind hier:
- scale_pos_weight – adressiert das Klassenungleichgewicht durch Hochgewichtung der Minderheitsklasse
- max_depth – kontrolliert die Modellkomplexität, um Overfitting zu verhindern
- enable_categorical – ermöglicht XGBoost, kategoriale Merkmale direkt zu verarbeiten
Und das war's für unseren ersten Prototyp. Der Trainingsprozess ist bemerkenswert unkompliziert, sobald die Datenaufbereitung abgeschlossen ist.
Bewertung der Modellleistung
Wir evaluieren das trainierte Modell auf unserem zurückgehaltenen Testset und erhalten folgende Ergebnisse:
Test ROC AUC: 0.8375
Classification Report:
precision recall f1-score support
Bad Credit (0) 0.56 0.85 0.67 59
Good Credit (1) 0.91 0.70 0.79 135
accuracy 0.75 194
macro avg 0.73 0.78 0.73 194
weighted avg 0.80 0.75 0.76 194
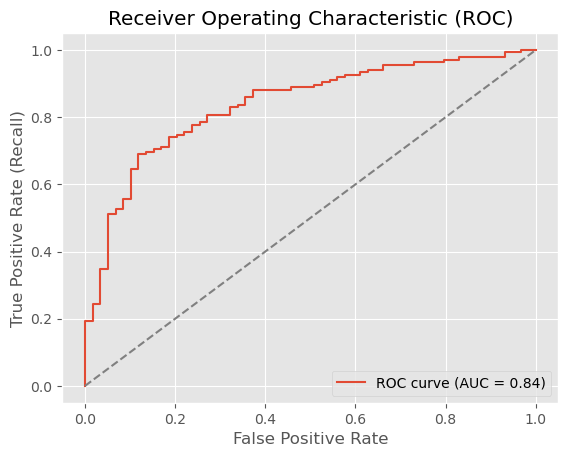
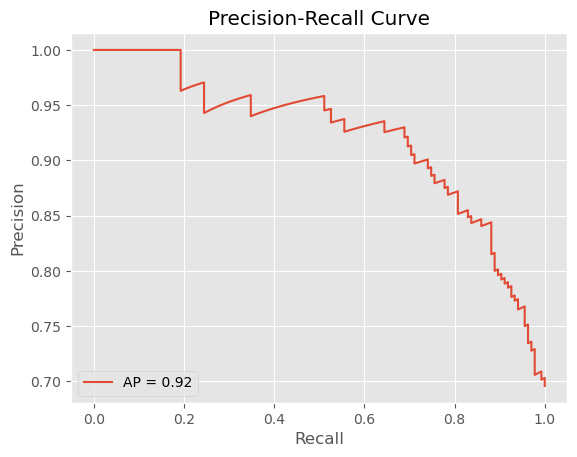
Unser ROC AUC von 0,84 ist solide für einen ersten Prototyp und zeigt, dass das Modell zwischen guten und schlechten Kreditrisiken angemessen unterscheiden kann. Zum Vergleich: Ein zufälliger Klassifikator würde 0,5 erreichen, während ein perfekter Klassifikator 1,0 erreichen würde.
Der Recall-Precision-Tradeoff ist hier besonders wichtig. Unser Modell erreicht einen Recall von 0,85 für schlechte Bonitätsbewertungen (Klasse 0), was bedeutet, dass es 85 % der Kunden, die in Zahlungsverzug geraten werden, korrekt identifiziert. Dies ist entscheidend für das Risikomanagement – ein schlechtes Kreditrisiko zu übersehen, ist teuer.
Dies hat jedoch seinen Preis: Die Precision für schlechte Bonität beträgt nur 0,56. Das bedeutet, dass das Modell nur in 56 % der Fälle richtig liegt, wenn es „schlechte Bonität" vorhersagt. Praktisch gesehen lehnen wir einige kreditwürdige Kunden ab (False Positives), was verlorene Geschäftsmöglichkeiten bedeutet.
Für ein Produktionssystem müssten wir die richtige Balance zwischen diesen Metriken basierend auf Geschäftsprioritäten finden. Ist es kostspieliger, ein schlechtes Darlehen zu genehmigen oder einen guten Kunden abzulehnen? Diese Entscheidung bestimmt, wo wir unseren Klassifikationsschwellenwert setzen.
Ist dies produktionsreif? Noch nicht ganz. Während 85 % Recall ein guter Start ist, würden wir in der Produktion typischerweise 90 %+ für die Minderheitsklasse anstreben, und wir möchten die Precision verbessern, um falsche Ablehnungen zu reduzieren. Dieser Prototyp zeigt jedoch, dass XGBoost mit sauberen Daten und angemessener Handhabung des Klassenungleichgewichts eine solide Grundlage für ein Credit-Scoring-System schaffen kann.
Nächste Schritte: Skalierung und Automatisierung
Während unser Prototyp vielversprechende Ergebnisse zeigt, gibt es noch Arbeit zu tun, bevor dieses Modell in einer Produktionsumgebung eingesetzt werden kann. Hier sind die wichtigsten Bereiche, die Aufmerksamkeit erfordern würden:
Modelloptimierung
- Hyperparameter-Tuning mit Cross-Validation, um zusätzliche Leistung herauszuholen
- Feature-Importance-Analyse zur Identifizierung, welche Attribute Kreditentscheidungen treiben
- Experimentieren mit verschiedenen Klassifikationsschwellenwerten zur Optimierung des Precision-Recall-Tradeoffs für Geschäftsanforderungen
Produktionsinfrastruktur
- Aufbau eines API-Endpunkts für Echtzeit-Credit-Scoring
- Implementierung von Modellüberwachung zur Erkennung von Performance-Drift im Laufe der Zeit
- Erstellung automatisierter Retraining-Pipelines, sobald neue Daten verfügbar werden
- Etablierung von Model Governance und Audit-Trails für regulatorische Compliance
Geschäftsintegration
- A/B-Testing des Modells gegen bestehende Kreditentscheidungsprozesse
- Definition klarer Eskalationsverfahren für Grenzfälle
- Erstellung interpretierbarer Erklärungen für Kreditentscheidungen (wichtig für regulatorische Compliance und Kundenvertrauen)
Der Weg vom Prototyp zur Produktion ist erheblich, aber mit sauberen Daten und einem soliden Basismodell haben Sie eine starke Grundlage, auf der Sie aufbauen können.
Dies ist Teil 2 unserer Credit-Scoring-Serie. Lesen Sie Teil 1 über die Grundlagen der Datenqualität, um zu verstehen, warum wir so viel Zeit mit der Datenbereinigung verbracht haben, bevor wir überhaupt das Modell berührt haben.
Der vollständige Code für dieses Tutorial ist auf Github verfügbar. Klonen, experimentieren und passen Sie ihn gerne für Ihre eigenen Anwendungsfälle an.
From Raw Data to Ratings: Building an XGBoost Credit Classifier in Python
How do you build an XGBoost credit classifier in Python?
- Data quality is critical for accurate credit models.
- Step-by-step from raw data through cleaning to model training.
- XGBoost achieves strong results (ROC AUC ≈ 0.84).
- A foundation for scalable, automatable credit scoring systems.
In our last post, we discussed the importance of data organization and quality. If you missed it, here's the key takeaway: poor data organization is one of the main reasons AI projects fail before they even start.
Incomplete, inconsistent, or biased data leads to unreliable results, no matter how advanced the model. In sensitive areas like credit scoring, clean and well-structured data is crucial for accuracy, fairness, and regulatory compliance. Automation and feature engineering only succeed when built on a solid data foundation.
The bottom line? Secure data quality first, then choose the right model. It doesn't work the other way around.
In this post, we'll implement a credit scoring prototype with XGBoost. Once the data is properly prepared, you'll see how straightforward model training can be. We'll cover the relevant code sections in this blog, but feel free to explore the complete source code on GitHub for deeper implementation details.
While production credit scoring systems in Germany require interpretable methods like logistic regression, this XGBoost prototype demonstrates best practices that are essential for any data scientist. In industry, teams routinely build gradient-boosted models first to establish a performance benchmark and identify the most predictive features, insights that directly inform the design of simpler, compliant models. Additionally, these same techniques apply to credit scoring in international markets and to internal risk modeling where regulatory constraints differ.
Preparing Your Data
We're using a financial dataset containing customer records with various attributes used to determine credit ratings of 'good' or 'bad'. The dataset includes both numerical features (income, age, loan amount) and categorical features (employment status, housing type, purpose of loan).
To simulate real-world conditions, we've intentionally introduced common data quality issues into the original dataset: missing values, duplicates, outliers, and inconsistent formatting. While the original data was pre-cleaned, these artificial imperfections allow us to demonstrate the full data cleaning pipeline you'd need in production environments.
As expected, there's a significant class imbalance, with the majority of customers rated 'good'. This mirrors real-world lending: most people don't default on their debts. While this is excellent news for lenders, it creates a substantial challenge for data scientists. Class imbalance makes it harder for classification models to learn patterns in the minority class, often resulting in models that simply predict "good" for everyone while achieving deceptively high accuracy.
The Data Cleaning Process
To address these issues, we run a comprehensive data cleaning pipeline (german_credit_cleanser.py) that systematically checks for:
- Duplicates – which can artificially inflate certain patterns and bias the model
- Missing values – requiring imputation or removal based on the proportion missing
- Invalid values – such as negative ages or loan amounts exceeding reasonable thresholds
- Outliers – extreme values that may represent data entry errors rather than legitimate edge cases
- Data type consistency – ensuring numerical fields are numeric and categorical fields are properly encoded
After running the cleaning script, we end up with a refined dataset of 968 rows and ready for model training. While we've lost some records in the cleaning process, what remains is reliable data we can trust to build meaningful predictions.
Training Your Model with XGBoost
Data Preprocessing Steps
With clean data in hand, we can move to model training. Before fitting the model, we need to prepare the data in the appropriate format for XGBoost.
First, we encode the target variable (good/bad credit rating) as numerical labels using sklearn's LabelEncoder:
# Target encoding
y = df['target'].astype(str)
le = LabelEncoder()
y_enc = le.fit_transform(y)
X = df.drop(columns=['target'])
Next, we perform a stratified train-test split (80/20) to maintain the same class distribution in both sets and prevent data leakage:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
For categorical features in our dataset, we convert them to pandas' category dtype, which XGBoost can handle natively without requiring one-hot encoding:
categorical_columns = ['employment_status', 'housing', 'purpose']
for col in categorical_columns:
X_train[col] = X_train[col].astype('category')
X_test[col] = X_test[col].astype('category')
Finally, we calculate the scale factor for class imbalance, which XGBoost will use to give more weight to the minority class during training:
scale_pos_weight = (y_train == 0).sum() / (y_train == 1).sum()
Model Training
We instantiate and train the XGBoost classifier with optimized hyperparameters:
model = XGBClassifier(
scale_pos_weight=scale_pos_weight,
max_depth=6,
learning_rate=0.1,
n_estimators=100,
enable_categorical=True,
random_state=42
)
model.fit(X_train, y_train)
The key parameters here are:
- scale_pos_weight which addresses class imbalance by upweighting the minority class
- max_depth which controls model complexity to prevent overfitting
- enable_categorical which allows XGBoost to handle categorical features directly
And that's it for our first prototype. The training process is remarkably straightforward once the data preparation is complete.
Evaluating Model Performance
We evaluate the trained model on our held-out test set and obtain the following results:
Test ROC AUC: 0.8375
Classification Report:
precision recall f1-score support
Bad Credit (0) 0.56 0.85 0.67 59
Good Credit (1) 0.91 0.70 0.79 135
accuracy 0.75 194
macro avg 0.73 0.78 0.73 194
weighted avg 0.80 0.75 0.76 194
[Figure 2: ROC curve showing AUC of 0.84]
[Figure 3: Precision-Recall curve highlighting the precision-recall tradeoff]
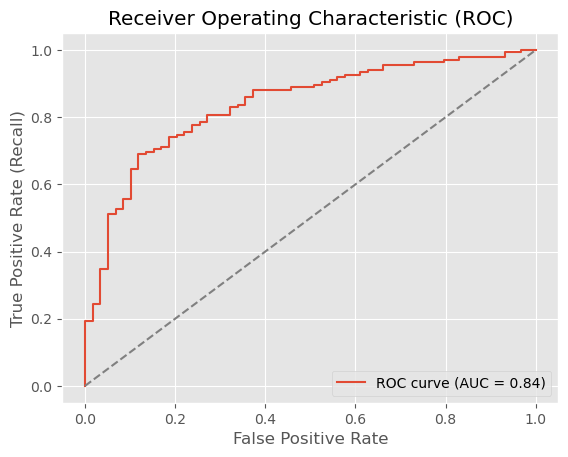
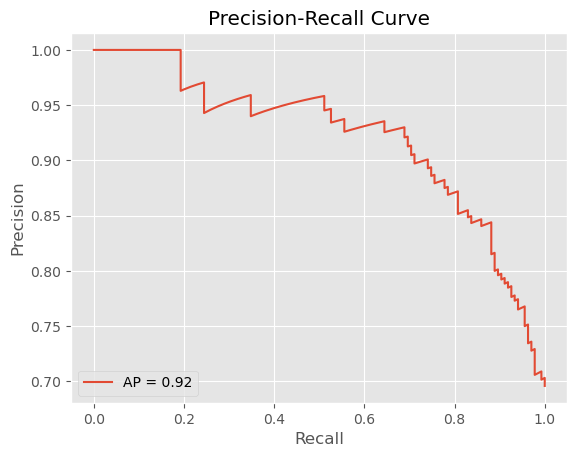
Our ROC AUC of 0.84 is solid for a first prototype, indicating the model can distinguish between good and bad credit risks reasonably well. For context, a random classifier would achieve 0.5, while a perfect classifier would achieve 1.0.
The recall-precision tradeoff is particularly important here. Our model achieves a recall of 0.85 for bad credit ratings (class 0), meaning it correctly identifies 85% of customers who will default. This is critical for risk management—missing a bad credit risk is expensive.
However, this comes at a cost: precision for bad credit is only 0.56. This means that when the model predicts "bad credit," it's only correct 56% of the time. In practical terms, we're rejecting some creditworthy customers (false positives), which means lost business opportunities.
For a production system, we'd need to find the right balance between these metrics based on business priorities. Is it more costly to approve a bad loan or to reject a good customer? That decision drives where we set our classification threshold.
Is this production-ready? Not quite. While 85% recall is a strong start, we'd typically aim for 90%+ in production for the minority class, and we'd want to improve precision to reduce false rejections. However, this prototype demonstrates that with clean data and appropriate handling of class imbalance, XGBoost can build a solid foundation for a credit scoring system.
Next Steps: Scaling Up and Automation
While our prototype shows promising results, there's still work to be done before deploying this model in a production environment. Here are the key areas that would require attention:
Model Optimization
- Hyperparameter tuning with cross-validation to squeeze out additional performance
- Feature importance analysis to identify which attributes drive credit decisions
- Experimenting with different classification thresholds to optimize the precision-recall tradeoff for business needs
Production Infrastructure
- Building an API endpoint for real-time credit scoring
- Implementing model monitoring to detect performance drift over time
- Creating automated retraining pipelines as new data becomes available
- Establishing model governance and audit trails for regulatory compliance
Business Integration
- A/B testing the model against existing credit decision processes
- Defining clear escalation procedures for edge cases
- Creating interpretable explanations for credit decisions (important for regulatory compliance and customer trust)
The journey from prototype to production is substantial, but with clean data and a solid baseline model, you have a strong foundation to build upon.
This is Part 2 of our credit scoring series. Read Part 1 on data quality foundation to understand why we spent so much time on data cleaning before even touching the model.
The complete code for this tutorial is available on Github. Feel free to clone, experiment, and adapt it for your own use cases.
Kommentar schreiben